数字人中的物理学
各位亲爱的同学们,大家好!非常荣幸能够邀请大家踏入这场精彩纷呈的科普盛宴,一同开启探索未知世界的奇妙之旅。想象一下,在这个日新月异的时代,人工智能与计算机技术如同魔法般,让我们的生活舞台跃动着前所未有的活力与色彩。从电视荧幕到电脑屏幕,再到掌心的智能手机,各式各样的数字人正以最生动的姿态,走进我们的视野——无论是引领美妆潮流的虚拟偶像“柳叶熙”,还是才华横溢、能奏出天籁之音的虚拟大学生华智冰,乃至北邮自主研发的耐心陪伴小朋友学习普通话的红雁国音数字人教师言小腾。这些数字人不仅成为了我们生活中的亮点,更是科技进步的璀璨见证。

那么,亲爱的同学们,你们是否好奇过,这些仿佛拥有灵魂的数字人背后,究竟隐藏着怎样的物理奥秘与科学原理呢?今天,就让我们化身为小小科学家,携手揭开这层神秘的面纱,深入探索物理学与媒体技术如何携手并进,共同编织出数字人视频生成的壮丽画卷。准备好了吗?让我们带着好奇心与求知欲,一同踏上这场探索物理学与媒体技术交融的奇妙旅程,去发现、去体验、去创造属于未来的数字奇迹!
1 数字人的声音——物理与技术的交响
1.1 声音的产生与传播
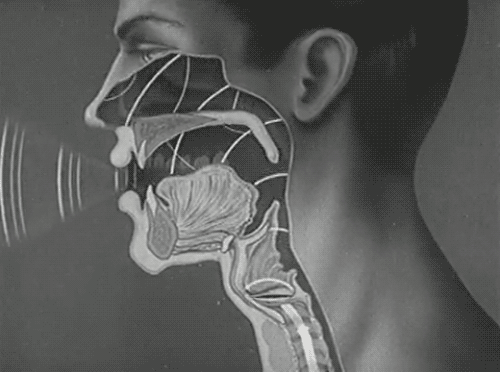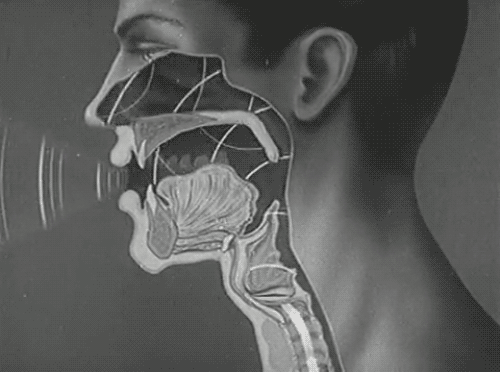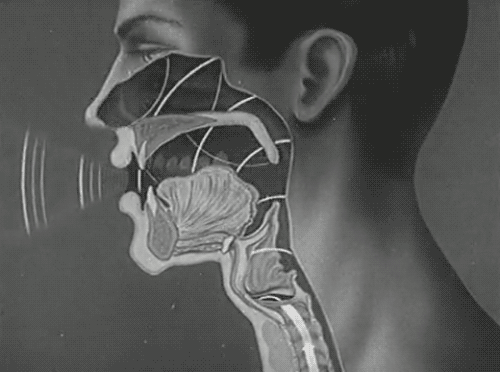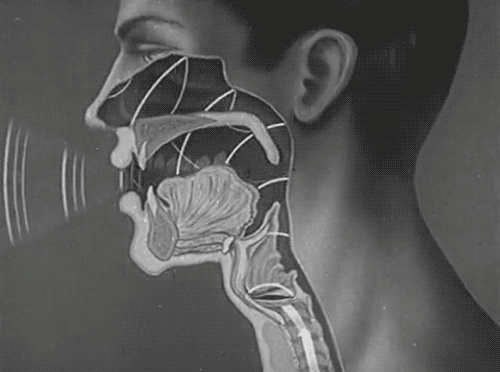
数字人要和我们进行交互,最重要的能力就是会说话。那么,我们怎么才能做到让数字人发出和人类相仿的说话声呢?在解答这个问题之前,我们首先来回顾一下人类是怎么发声的:当我们想要表达某个想法时,大脑会先构思出想要传达的信息。接着,这些信息就像密码一样,被转换成一系列的音素、韵律、响度和基音周期的变化。这些“密码”随后被转化为神经肌肉指令,指导声带在合适的时机振动,形成基础频率,这是声音产生的起点。然后通过调整声道、软颚、口腔和舌头等器官的形状和位置来对声音进行调制和滤波,最终发出我们想要的声音。
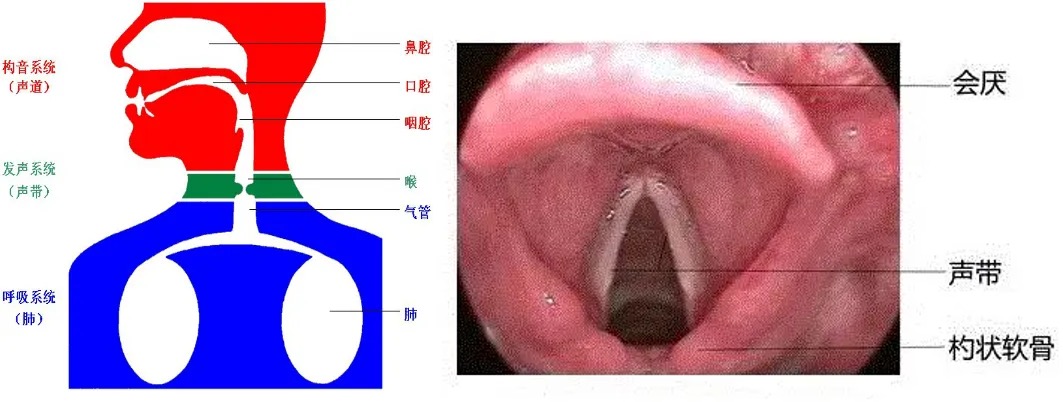
1.2 声波的奥秘
我们发出的声音本质上是以物理波的形式存在,这一现象赋予了声波这一术语的准确定义。声波作为一种独特的纵波类型,其振动方向与传播方向保持严格一致,自声源发出后,广泛传播至周围空间,实现无处不在的覆盖。声波的核心特性可归纳为频率、振幅与波形三大要素:频率作为声音的音高决定性因素,其数值高低直接关联到声音的尖锐程度,例如女性声音的频率普遍较高,呈现出更为尖细的音质;振幅则量化了声音的响度,声音强度的增大直接对应着振幅的增大;而波形,作为声音形态的精确描绘,不仅展示了声音的时域与频域特征,还为实现声音的数字化处理与分析提供了可能,进而奠定了利用计算机算法模拟并生成语音波形,最终驱动数字人发声的技术基础。
1.3 语音合成技术
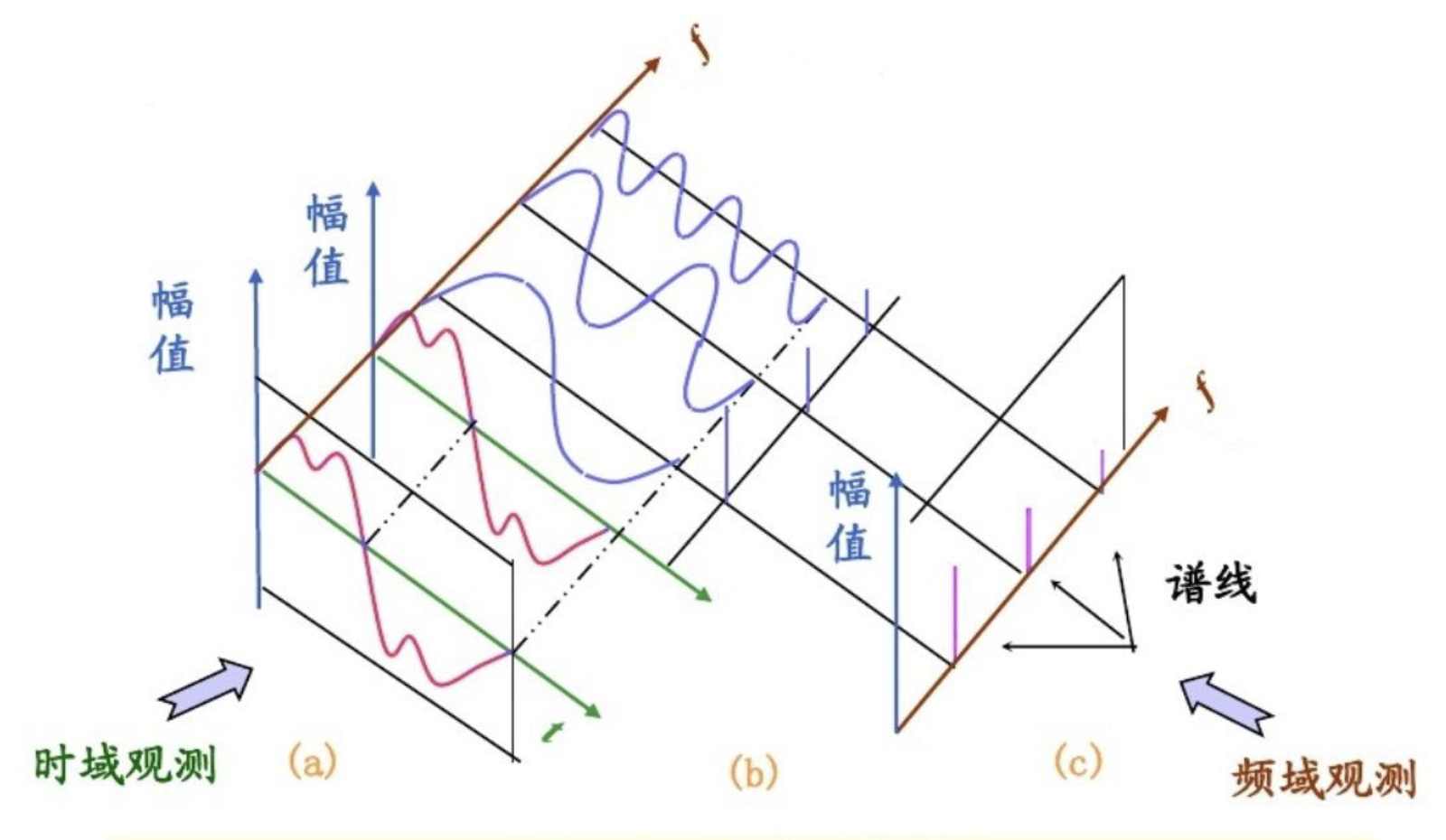
人类话语声涉及复杂多变的语音波形,该波形是多重频率成分的复合体现,直接以时域波形呈现容易造成成分混叠,难以细致区分。而采用频域表征策略则能清晰展现各频率成分的离散分布,从而大幅降低了语音信号数字化分析的门槛。在频域图谱中,最低频率分量,即所谓基频,扮演着至关重要的角色,它不仅界定了声音的基本音调高低,还深刻影响着声音的尖锐程度。此外,频域内频率密度相对集中的区域,明确指示了共振峰的存在及其频率范围,这一特征对于塑造语音的独特音色具有决定性作用。
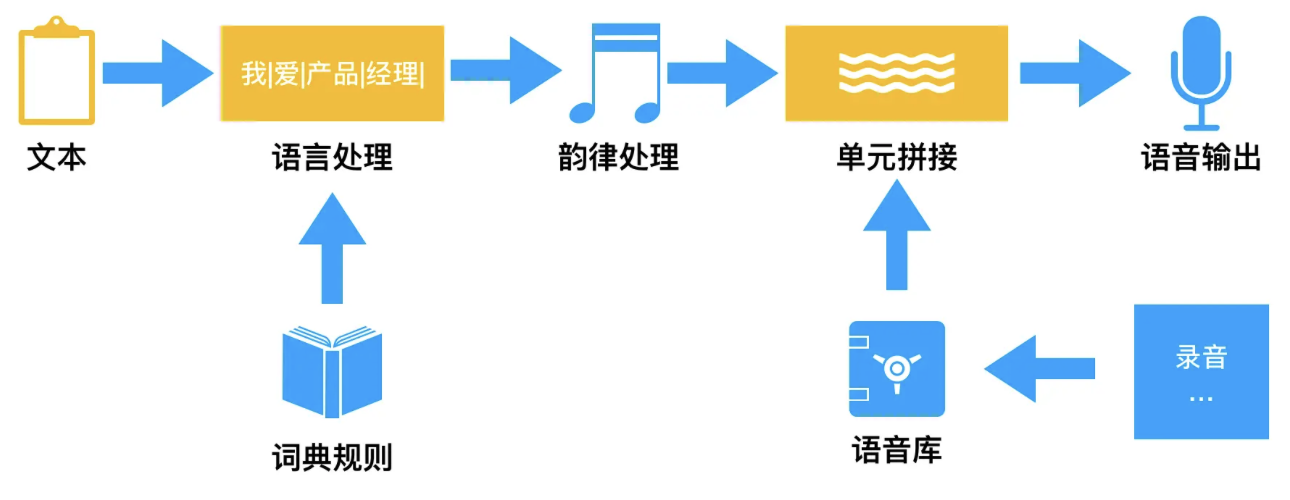
为使数字人能够发出接近人类水平的语音,语音合成技术应运而生,该技术核心在于构建一个高精度的声学模型,该模型旨在精准模拟人类声道的复杂物理特性,涵盖声道的几何形态、尺寸规格乃至共振峰模式等细微差异,从而合成出与人类语音高度一致的音频输出。在语音合成的众多方法中,单元挑选与波形拼接技术尤为常见且高效,它通过精心挑选符合合成需求的音频片段,并依据特定规则进行无缝拼接,以构建出目标语音信号。
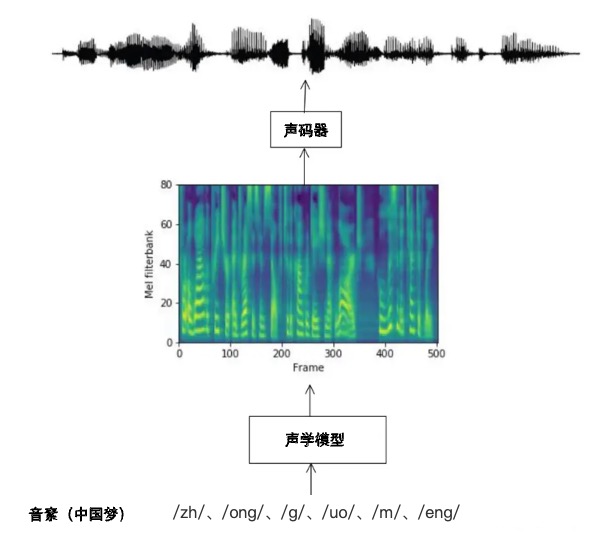
随着人工智能技术的发展,以深度学习技术为基础的语音合成成为主流方法。在语音合成过程中,对原始人声样本的精准数字化处理与高效存储是关键环节。通过自然语言处理技术将连续文本拆分为独立的文字乃至更细微的音素单元后,系统使用预先训练好的深度学习模型直接生成与文本相匹配的语音编码数据。这些语音编码数据经过解码过程后变为模拟语音信号,再由数字人“说出来”。
1.4 语音的数字化处理
为了让计算机能够处理语音信号,我们首先需要对其进行数字化处理。这一过程包括采样与量化两大核心操作。

具体而言,采样过程可类比于时间轴上的精确快照捕捉,它在固定的时间间隔内记录下声音信号的状态,从而将连续的语音流分割为一系列离散的样本点;而量化则是随后进行的数值编码过程,它将每个样本点的连续幅度值映射为有限范围内的离散数值,从而实现了声音信号的数字化表示,便于计算机进行存储、传输及后续处理。一旦语音信号完成数字化转换,其原始编码数据即可利用傅里叶变换等经典频谱分析方法和梅尔频率倒谱系数等现代音频特征提取技术,深入解析并提取出音调、音色、音量等关键声学特征。这些特征不仅深刻反映了语音信号的本质属性,也为数字人语音合成技术提供了坚实的理论基础与技术支持。
采样是语音信号处理中的关键技术,它将连续的声波信号转化为离散的数字信号,顾名思义,它要做的事情就是以固定的时间间隔去捕捉这些语音信号连续起伏的幅值点。而这些固定的时间间隔被称为采样周期,采样周期的倒数就是我们熟知的采样频率。
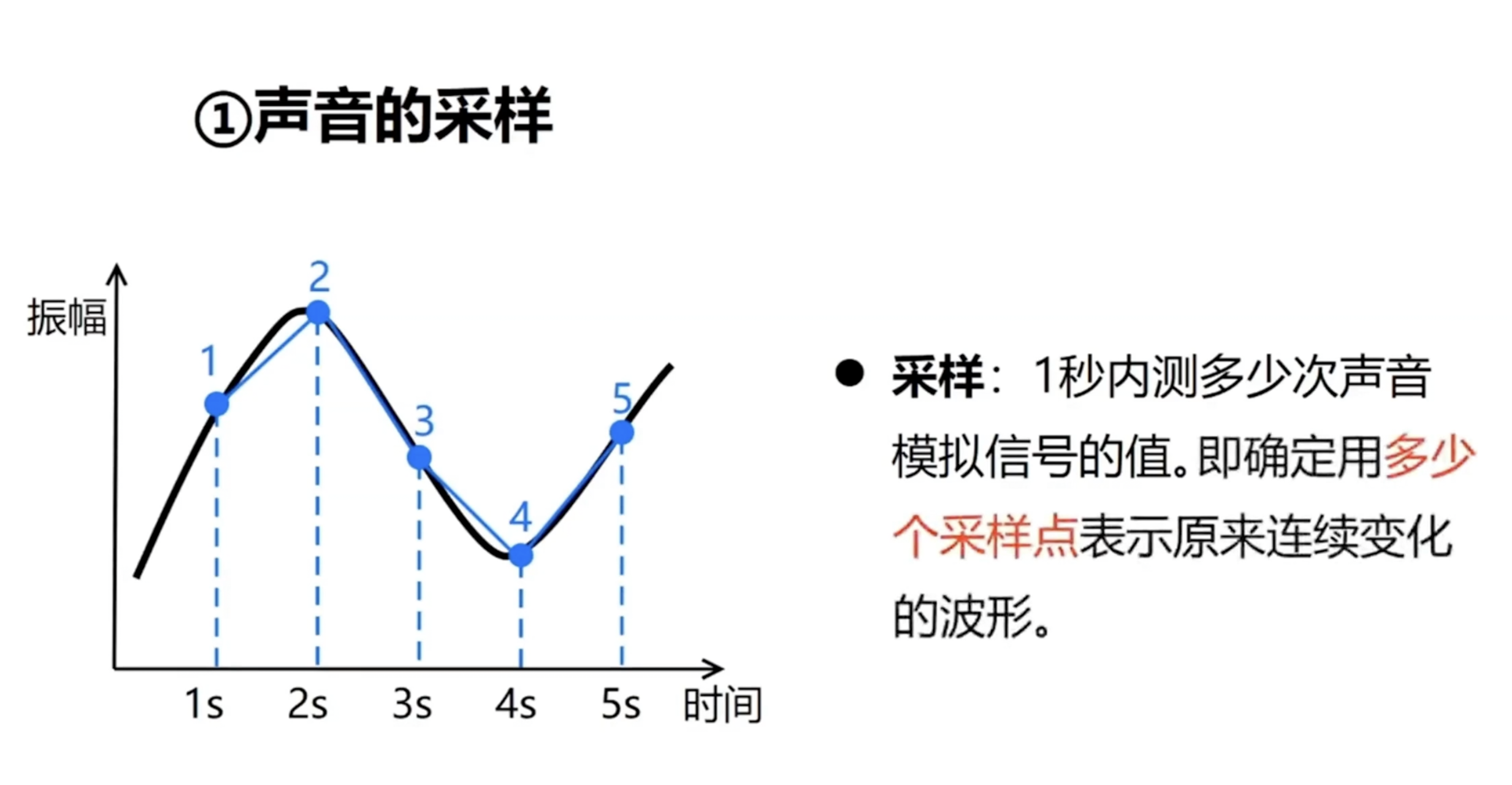
你可能好奇,既然是采样,肯定会存在没被采样到的语音信号,那么会不会导致原始的语音信息被遗漏了呢?不用担心,科学家们已经总结了一个重要的科学定理——采样定理。它告诉我们,只要采样频率高于原始信号最高频率的两倍,我们就能完整地保留声音信息,不会造成任何损失。因此,只要语音信号的采样过程符合采样定理,即可保证最终语音合成的声音基本不会失真。
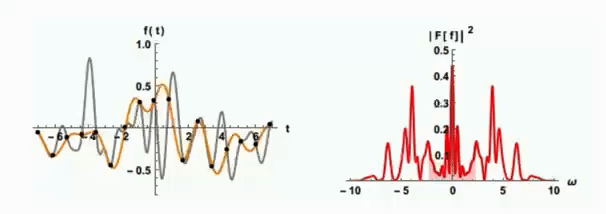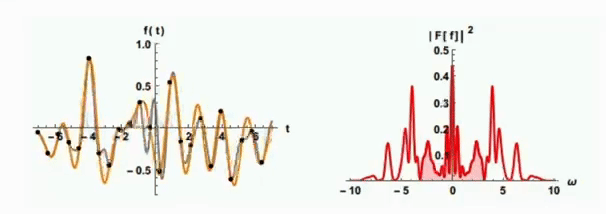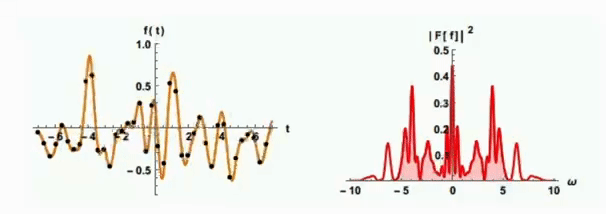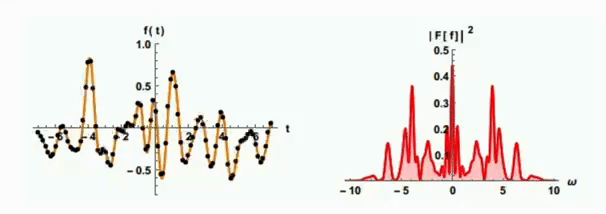
我们再来关注一个问题,在日常说话、演讲、辩论等不同场合下我们发出的声音的幅值变化速度各不相同。我们在演唱一些舒缓的经典老歌时声音的幅值变化相对较慢,而在辩论的时候语音幅值变化极快。大家可以想一想,如果我们仅仅使用采样的方式对唱歌这类幅值变化缓慢的语音信号进行离散化,虽然时间域上信号变得离散,但幅度上仍可能保持连续,导致数据量庞大。
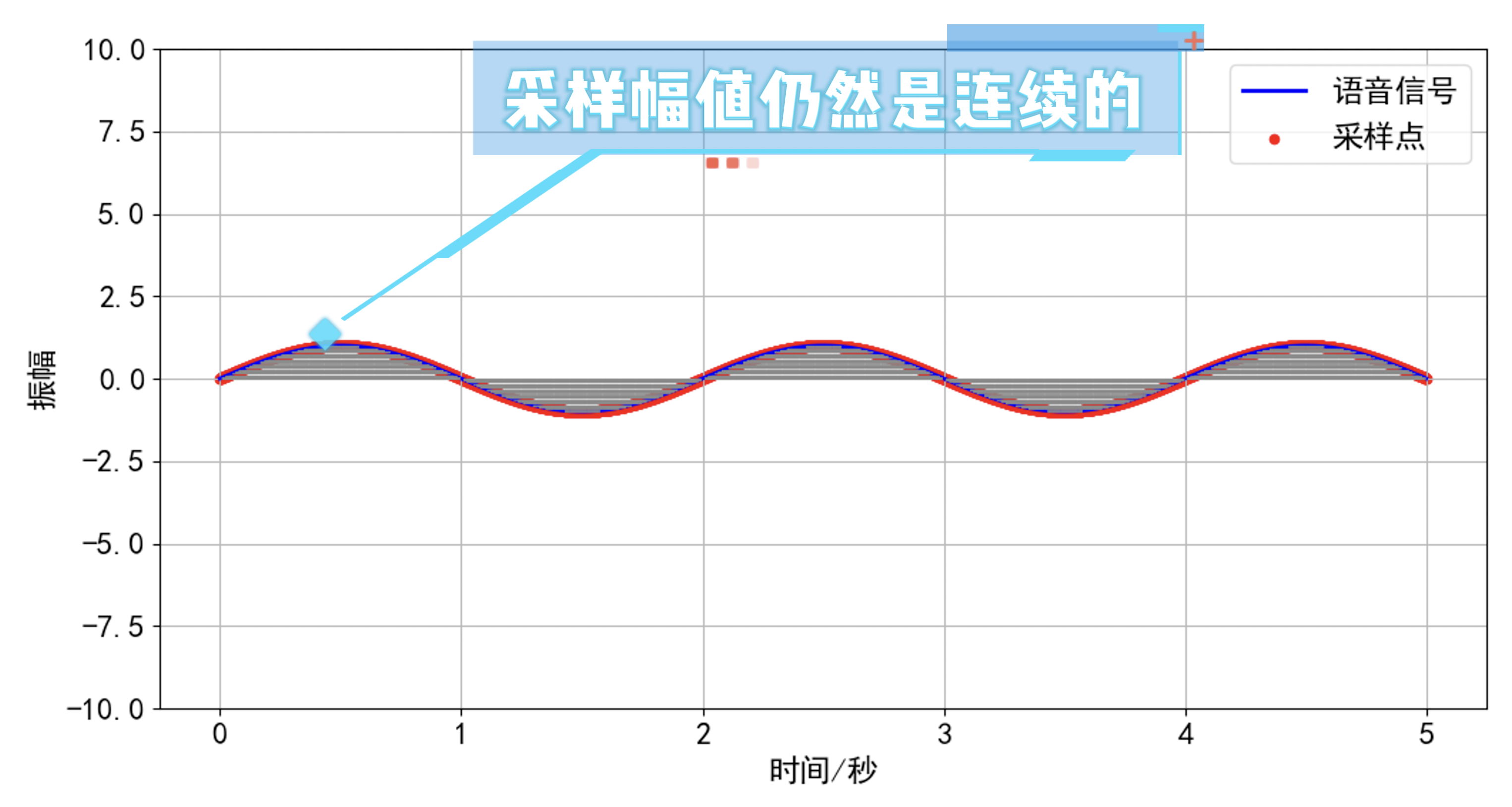
为了解决这个问题,我们引入了“量化”技术。量化是将信号波形的幅度值进行离散化处理,它通过一个量化器将信号的幅度值划分为有限的区间,每个区间内的样本点都使用相同的幅度值——即量化值来表示。通常,量化值采用二进制编码,量化字长则取决于用于表示量化值的二进制位数。这种技术能有效减少数据量,同时保留声音的主要特征。
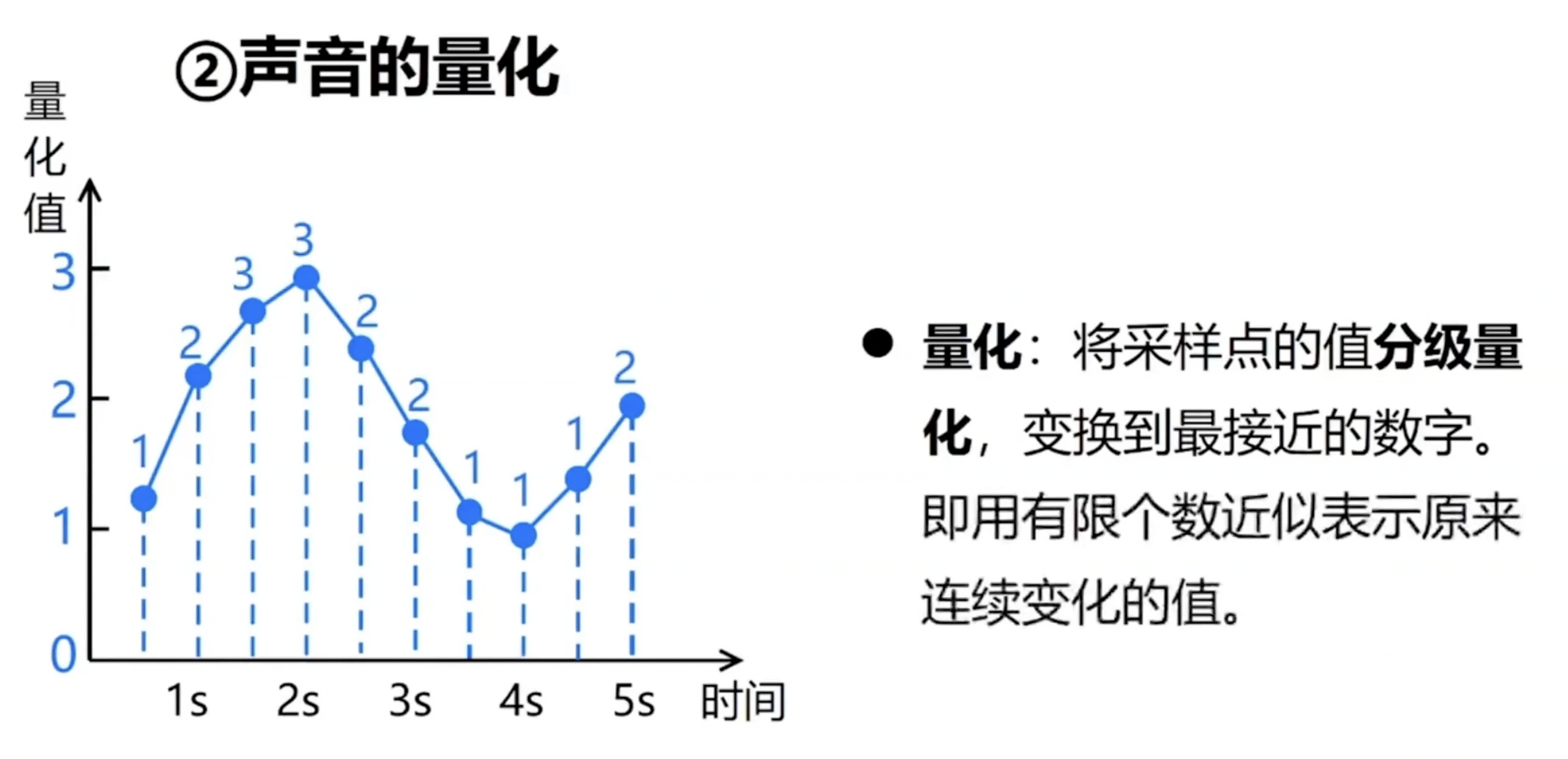
高质量的数字声音,虽然经过精心的采样和量化处理,但其数据量依然庞大。为了有效存储和便于网络传输,我们需要进行压缩编码。这一过程旨在以最小化的比特数维持声音的高音质和清晰度,同时巧妙利用掩蔽效应剔除冗余信息。编码过程中,码率是一个关键指标,代表每秒传输语音信号所需的比特数,它决定了语音编码的速率分类,如高速率、中高速率等。编码方法则分为波形编码、参数编码和混合编码。波形编码力求还原原始波形,通常速率较高;参数编码则从听觉感知出发,追求效果接近原声,速率较低;而混合编码则结合两者优点,追求音质与速度的平衡。我们常说的“无损音频”,如传统CD格式的16bit/44.1kHz,之所以无损,是因为其频响范围完全覆盖人耳可听范围,确保音质完美。

经过采样、量化与编码三大步骤之后,语音信号已经被转化为计算机可直接识别与操作的数字形式。在人与数字人交互的过程中,计算机从大规模预训练模型或特定程序中提取出数字人需“发声”的文本内容。然后通过语音合成技术直接生成与文本相匹配的语音编码数据。
这些语音编码数据要能变成模拟语音信号由数字人说出来,就需经历解码过程了。解码,就是将数字信号变回模拟信号的过程,它分为硬解码和软解码两种方式。硬解码借助专用解码器,直接将音频压缩数据转化为模拟信号,确保音频输出低延迟且高质量。而软解码则依赖于设备的软件解码器,如MP3和AAC等格式的文件,都能通过它灵活解码并播放,具有极高的可配置性。最终,解码后的模拟信号经过放大器增强,再由喇叭振动,将声音完美地传递给我们。
通过上面的讲解,我们了解了如何使用语音合成技术让数字人开口说话,那么数字人又是如何根据这段语音来生成对应的脸部和身体的呢?接下来我们就来揭秘一下数字人的身体是如何生成的,其中又包含了什么样的物理学原理呢?
2 数字人的形象——物理与技术的融合
2.1 精准采集与数字重建
在构建仿真数字人形象的过程中,首要步骤是精准采集目标真人的形象数据,随后运用计算机技术深入解析其肢体动态、面部表情等关键特征。基于这些详尽的特征分析,借助高效的计算机图形渲染技术,实现数字人模型的精确重建。在实际操作中,通常采用手机或专业相机作为采集工具,这些设备能够模拟人类视觉机制,通过镜头精准捕捉光线信息,并依赖内置的感光元件将光信号高效转换为电信号。随后,利用图像处理算法,将捕获到的人物面部细节与身体轮廓转化为高精度的数字图像,为后续的数字人构建奠定坚实基础。

拍摄完毕的人体图像,会经过一系列严谨而精细的数字化处理流程,这一流程涵盖了图像的数字化转换、高效压缩以及专业编码等步骤,最终将其转化为可便捷存储与管理的编码文件。这些文件广泛采用如MP4、AVI、MOV等标准化格式,这些格式不仅能够忠实地保留人物的原始清晰度和丰富细节,还实现了文件体积的大幅缩减,从而在确保图像质量的同时,优化了存储空间的利用效率,降低了存储的需求。

2.2 三维重建技术:神经辐射场(NeRF)
采集完成的真人视频就可以用来制作高保真数字人了,数字人的生成也涉及复杂的图像处理、机器学习及三维建模技术,在这儿,我想重点给大家介绍一种能够非常真实还原真人形象的三维重建技术——神经辐射场(Neural Radiance Fields,NeRF)。NeRF像是一位精通物理学的艺术家,从多视角的图像中捕捉光线与场景的微妙互动。通过深度学习,NeRF这位数字世界的超级记忆大师,能够捕捉并记住来自四面八方的照片信息,随后在其内部空间构建一个细腻的三维宇宙,它不仅记录了空间中的每一个点,还捕捉了光线在这些点上的颜色、密度乃至传播方向。

在NeRF的世界里,光线按照现实的物理规则,沿着既定的路径穿梭于三维场景之中。它们与场景中的物体相遇、碰撞、反射、折射……每一次交互都产生着新的光影效果。体渲染技术则是将这一系列光影效果转化为可视图像的关键步骤。它就像是一位摄影师,用镜头捕捉并记录下光线在三维场景中的每一次舞动。NeRF能够精准地预测出三维场景中每个点的颜色和透明度信息,然后通过体渲染技术,将这些信息完美地转化为二维图像,让我们在屏幕上就能感受到三维世界的魅力。
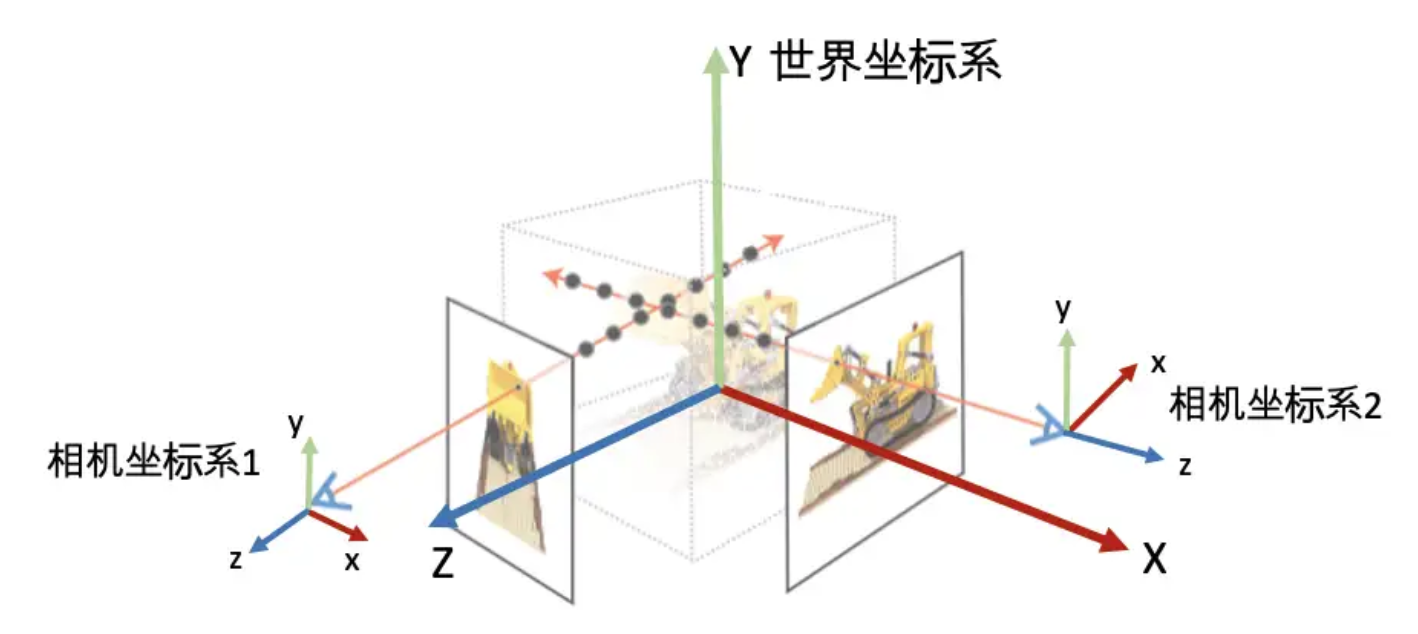
2.3 位置编码与精细建模
为了更准确地描述三维世界中的每一个点,NeRF引入了位置编码技术。这就像是为每个点穿上了一件独特的身份标识服,上面记录着它的位置、特征等。通过位置编码,神经网络能够更加容易地识别并记忆这些点的信息,从而构建出更加精细的三维场景。

面对庞大的三维数据海洋,NeRF采用了分层体素采样的策略。这就像是在大海中捕鱼时使用的渔网一样,先撒下一张大网进行粗略的捕捞;然后在发现鱼群聚集的区域再撒下更密集的小网进行精细捕捞。通过分层体素采样技术,NeRF能够在保证渲染质量的同时大大提高计算效率。
3 数字人的动态生成——语音与动作的同步
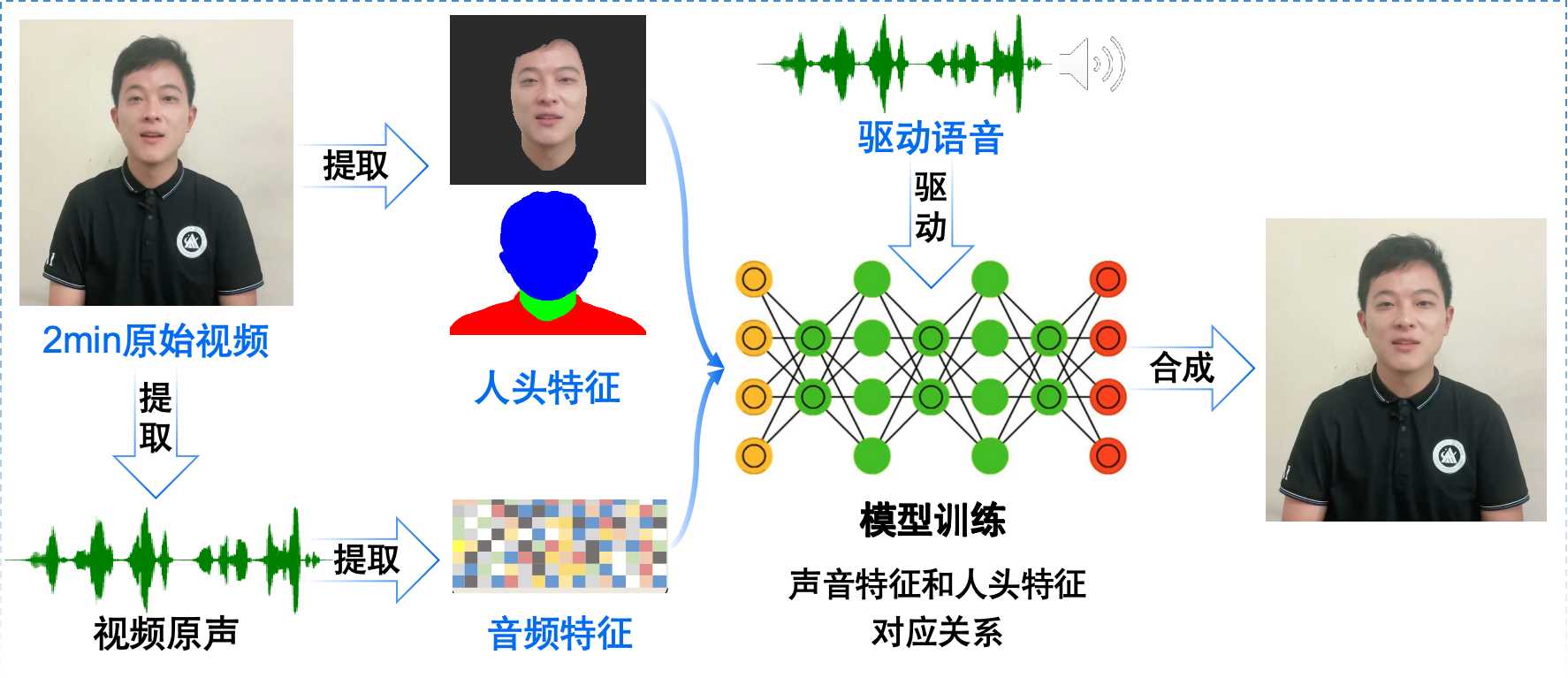
3.1 特征提取与模型训练
在数字人动态生成的过程中,我们需要从采集的真人视频数据中提取出有用的特征,这些特征和数字的口型、表情以及姿态相关联。然后使用数字化语音数据以及对应的人物视频数据来训练NeRF模型,从而构建一个掌握语音与面部表情、口型以及肢体动作之间对应关系的神经网络模型。
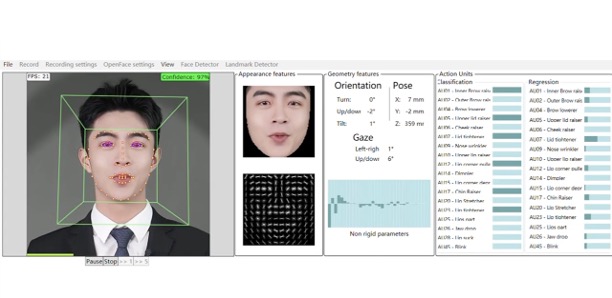
3.2 动态生成与视频合成
训练好之后的NeRF模型就可以根据输入的语音音频来逐帧预测出对应的口型和面部表情,然后使用体渲染技术将三维数据转化为二维图像,最后再逐帧保存为数字人讲话视频。这样,我们就可以得到一个嘴形、表情以及肢体动作和语音完全同步的高保真数字人了。
4 结语
在本次的科普课堂上,我有幸带领大家深入探索了一个引人入胜的主题——数字人是如何诞生的。通过这一旅程,我们不仅揭开了人工智能神秘面纱的一角,还详细阐述了其中所蕴含的物理学原理。我相信,经过这次学习,大家对于人工智能这一前沿科技领域定能拥有更加全面且深入的理解。最后,衷心感谢每一位同学的观看与陪伴。你们的支持是我不断前行的动力,再见!
互动问题:
- 除了课程中讲到的语音合成技术,大家还知道哪些和音频处理以及交互相关的人工智能技术?一起来探讨一下吧!
- 课程中讲到了使用音频驱动数字人形象动起来的跨模态数据对齐方法,同时也提到了NeRF这种三维重建技术。接下来大家可以继续讨论一下是否还有基于其他模态的数字人驱动方法?人体图像的生成是否还有别的替代技术?